













機器學習怎麼學?
文:黃正傑 2020-07-27
發布時間: 2020-07-27 15:48:00

不論是大數據分析、人工智慧、乃至於機器智慧的發展,背後的重要核心技術就是「機器學習」。那麼,機器要如何學習呢? 本文簡要介紹機器學習的步驟、途徑、方法,並指出機器學習的兩個挑戰。
機器學習是甚麼?
在之前,我們談到現今大數據分析、人工智慧、乃至於機器智慧的發展,背後的重要核心技術就是「機器學習」(machine learning)。顧名思義,「機器學習就是讓機器/電腦從過去經驗(數據)中,學習如何分類(辨認)或預測(數值)」。例如:從歷史銷售數據預測下一季銷售額、從大量設備運轉狀況,預測設備剩餘壽命等;從大量圖片資料中辨認是狗或是貓;從大量手寫數字中,辨認出0-9數字。
事實上,前篇所提及的數據挖掘KDD就是根基於「機器學習」方法。現今,「機器學習」方法不但包含了傳統數據挖掘的聚類、分類、回歸、依賴模型,更進一步涵蓋了分析圖片、文字等非結構化數據的分析方法。
機器學習的步驟:訓練(歸納學習)與部署(推論預測)
機器學習的步驟為何呢? 可以簡單地分為兩個階段:
1. 訓練模型建立階段: 數據科學家根據領域場景、工作項目類型,進行數據蒐集、轉換、演算法選擇、乃至於校調與建立模型。最後,數據科學家評估訓練結果好壞,選擇最適當的訓練模型(trained model)。
2. 模型部署推論階段:數據科學家或資訊工程師將訓練模型部署為資訊應用服務。之後,當新動物圖片、新設備狀況、下季銷售狀況等數據餵入訓練模型服務,即可進行推論(inference),產生分類或預測結果。預測的結果可以利用應用程式邏輯產生為數值、清單或者是動態圖形等展現方式。
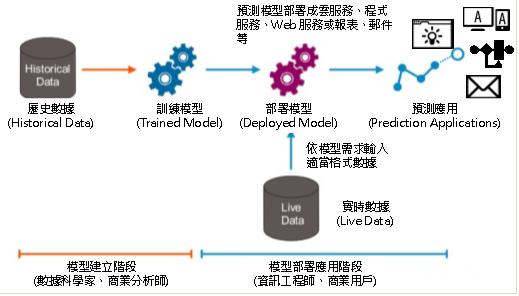
圖、機器學習步驟與階段(黃正傑,「大數據、AI應用趨勢與R語言案例分析」,2019)
機器學習的途徑: 監督與非監督
要如何訓練機器從資料中學習,進而產生訓練模型呢? 一般來說,有兩種途徑,一種稱為監督式學習(supervised learning)、另一種為非監督式學習(unsupervised learning)。
1. 監督式學習:
監督式學習必須給予機器一系列影響因子的特徵(features)及結果標籤(labels)的數據進行訓練。例如:針對設備進行剩餘壽命預估,需要一系列設備的溫度、馬達轉速、設備參數等特徵、及設備實際年限結果的組合數據。過濾垃圾郵件,可能需要被人們標籤後,放在「垃圾郵件箱」的許多郵件標題文字(文字作為特徵)的組合。之後,我們就根據大量的「特徵、標籤」的配對組合,選擇適當演算法,建立訓練模型。
當然,如何從雜亂資料中,進行特徵、標籤的萃取、選擇、轉換,仰賴數據科學家,也仰賴各種領域專家(如:某種機器設備、某種生產製程專家)協助進行。特別在非結構化的數據,諸如:圖片、文字、聲音,亦需要花費許多工夫進行特徵與標籤建立,即需要藉由人工方式分解圖片或文字的特徵或標籤化圖片或文字代表的意義。
2. 非監督式學習:
非監督式學習則希望不須設定標籤,即從雜亂資料中學習模式。例如:從顧客屬性、購買商品紀錄,區分不同市場顧客分群;從一群設備狀況,分析那些是異常設備。非監督式學習通常使用在發現群集或從大量資料中歸納可能特徵值,以做後續監督式學習。
此外,另一種新興的學習途徑稱為強化學習(reinforcement learning)。強化學習的標籤是動態的,根據各種回饋狀況而調整標籤值。例如:強化學習運用在遊戲或下棋,演算法可評估目前盤勢,找尋最大標籤值下個位置或動作(即不同特徵值),以取得勝利。強化學習適合運用在可動態評估情勢以計算標籤值的應用情境。
機器學習的方法: 決策樹、分群、類神經、深度學習
數據科學家在決定機器學習工作類型、訓練途徑及建立數據特徵/標籤組合配對後,則可以選擇適當的演算方法以建立訓練模型。機器學習方法非常多,包含決策樹(decision tree)、分群(clustering)、線性回歸(linear regression)、支援向量機(SVM)、類神經網路(ANN)、深度學習(deep learning)等。
當然,複雜的人工智慧問題,必須結合各種學習途徑、學習方法、乃至傳統非機器學習演算法、知識庫,才能達到預期結果。如:AlphaGo結合監督式深度學習、強化學習及人類棋譜盤勢知識等。這些常見機器學習方法已有許多的開源套件(如:R語言、Python)實現,讓數據科學家/工程師運用開發,有興趣的朋友可參考相關書籍或網站。
機器學習的挑戰:業務理解、數據準備
撇開缺乏適當員工、資料治理等企業層面考量外,實施一個大數據或機器學習的專案任務的最大挑戰,反而不是建立訓練模型或是應用服務部署。根據Rexer Analytics公司分析,一個大數據或機器學習的專案中,從業務需求拆解為數據分析問題的「業務理解」需要20%時間、根據數據分析問題進行數據蒐集、清洗等「數據準備」工作則需要36%時間,建立模型、應用部署僅分別佔20%、9%時間。
例如: 在工廠品質預測中,要根據業務情境決定哪些設備、物料特性是影響品質的要因? 這些特性又如何轉換為有效的特徵? 這些數據又如何蒐集與清理? 要減少「業務理解」、「數據準備」兩個工作時間,提高大數據、機器學習專案的成功機率,不能僅僅仰賴外部數據科學家。建議能訓練企業、工廠等具備領域經驗的經理人、工程師及IT人員初步理解大數據分析、機器學習概念,以加快與外部公司的數據科學家、分析師合作,更能提高機器學習專案的成功機率以及大數據分析的價值。
黃正傑
你喜歡挑戰不斷隆起的技術高原、探索無限寬廣的創新領域嗎? 那麼我們是同路人。
黃正傑,台大資管博士,協助鼎新進行前瞻技術研究與應用發展。歷經IT架構技術顧問、供應鏈管理顧問、軟體產業分析師等多項職務,並兼任文化大學助理教授。讓我們一起從創新與變革角度,探索新興技術!

更多案例



 我想瞭解
我想瞭解  我是用戶
我是用戶  我是夥伴
我是夥伴 





